TABMON is Europe’s largest network of acoustic recorders for biodiversity monitoring, with network-connected Bugg microphones recording audio 24/7 from Norway to Spain. This provides biodiversity insights at previously infeasible scales but also produces vast quantities of raw field data. Our aim is to develop reliable species identification models to process this data but the quality of model inference is dependent on the quality and quantity of labeled data. This raises a key question: given limited expert annotation resources, which audio samples should be selected for annotation and model development?
Active learning (AL)
AL is a machine learning approach that strategically selects the most informative samples for annotation, maximising the utility of limited, but critical, expert knowledge. AL enables models to be improved iteratively by focusing on the recordings that are most informative, improving the data-efficiency of model training.
Why Active Learning Matters
Large-scale biodiversity monitoring faces critical challenges that active learning can address:
- Limited annotation resources - As the quantity of data increases, the availability of expert annotators remains a severe constraint. Recent gains in computational bioacoustics are fundamentally data-driven, yet labelling acoustic data requires expert annotation.
- Data imbalance - Common species dominate recordings while rare, at-risk, or invasive species appear infrequently, creating severe class imbalance (long-tail distribution). Model performance tends to decay for tail species.
- Spatiotemporal variability - Recordings vary widely across locations and over time, requiring models that generalise across diverse conditions. Active learning directly tackles these challenges by more effectively using limited annotation resources.
Data Pipeline and Infrastructure
We’re developing a pipeline to process large-scale data streams, enabling storage and preparation of acoustic data for both ecological analyses and machine learning model development. This data pipeline is open-source and available on GitHub.
Active Learning Research
Our active learning work addresses key technical challenges:
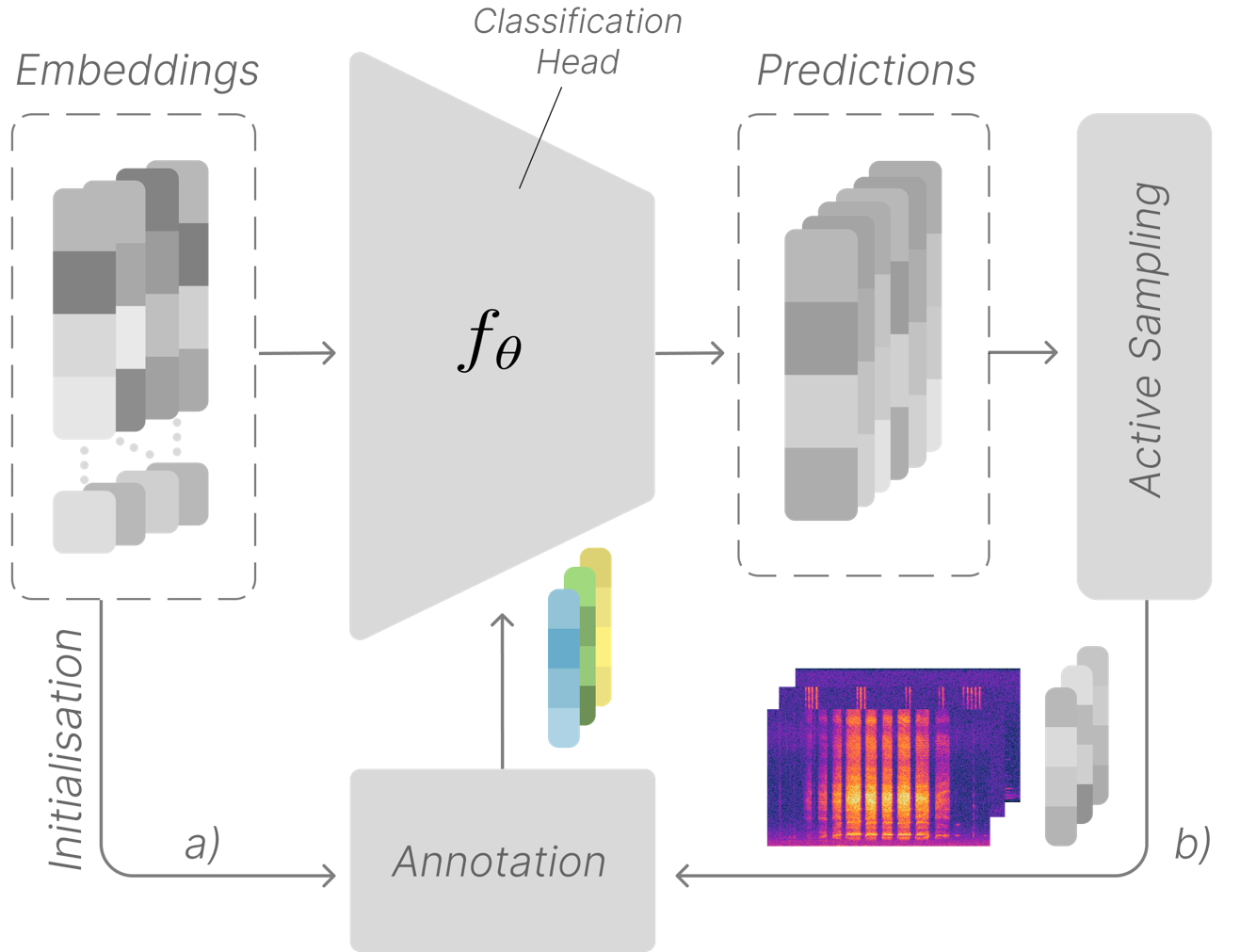
- Pre-processing and uncertainty quantification - All collected audio is processed by a pre-trained classification model (BirdNET) using the data-pipeline. Initial species predictions, confidence scores and the uncertainty (binary entropy) associated with model predictions are stored to a database along with associated metadata (e.g. time, location, etc).
- Active Sampling - The data pipeline provides a way to easily sample and export audio and pre-generated predictions from the database. Uncertainty sampling is a common method, where samples with high model uncertainty are selected for annotation. Our initial work compares uncertainty sampling as well as confidence sampling and various acoustic indices.
- Diversification - An important aspect of active learning is diversification. Selected samples must be both informative and non-redundant. Our initial results investigate diversification using embedding-based clustering and stratification across ecological gradients (pre-print now available). We are also investigating diversified sampling across predicted species labels pre-generated by BirdNET encouraging even sampling across long-tail predicted species distributions.
What’s Next
This project is ongoing and data is starting to be processed by expert annotators. The next steps are integrating expert annotated data into a fine-tune classification model. TABMON is carried out by a consortium of ecologists and machine learning researchers, and is funded by Biodiversa+.